分布式存储系统运行在复杂的集群硬件环境下,要求长时间不停机;遇到硬件设备发生故障时必须能够保证用户数据不丢失。因此在测试分布式存储系统中,稳定性测试和可靠性测试均要求设计一些硬件故障的测试场景。通常测试人员可以通过插拔物理设备,重启系统或者直接使用故障硬件来进行测试,但是这种方式不够方便,同时也无法进行自动化改造;这篇文章运用SystemTap动态跟踪工具,在内核注入故障代码,模拟物理设备故障。经过验证能够到达手工插拔物理设备构造故障场景的测试效果;同时使用接口方便,为进一步实现端到端自动化测试用例提供了基础性工具。
背景
故障测试是软件测试的重要场景。软件的运行环境越复杂,越有可能遭遇到各种各样的系统故障。CBS是一种分布式存储系统,对外提供块存储服务。CBS运行在服务器集群中,每台服务器直接连接多个物理磁盘。根据集群路由信息,CBS将虚拟磁盘的读写请求分发到物理磁盘上,实现用户数据的落盘与持久化。CBS运行环境包括主机,内存,磁盘,网络等物理设备,每一种设备均可能发生故障;尤其是磁盘设备的理论寿命为3万小时左右,而重要的用户数据寿命是远远超过磁盘寿命的。因此,在CBS测试项目中针对磁盘故障的可靠性和稳定性专项测试是质量保障体系中很重要的组成部分。这篇文章为测试过程中如何方便地模拟磁盘故障提供了一种解决方案。
原理
大家知道,Linux系统分为用户空间(User Space)与内核空间(Kernel Space);应用程序(Applications)无法直接访问物理设备的各种服务。如图一所示,应用程序运行在用户空间内,运行级别最低,必须通过内核提供的访问调用接口才能使用物理设备的服务。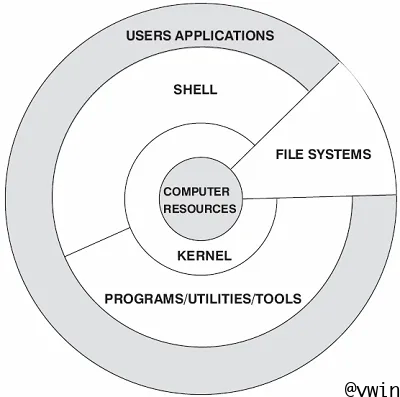
显然,若需要在系统中注入磁盘故障,存在两种方式;第一种方式最简单,直接使用一块坏盘,但是这种方式很不方便,需要插拔磁盘同时无法实现自动化,另外成本也不小。第二种方式是在内核中通过阻断磁盘处理程序中部分关键节点来模拟磁盘故障,通过内核模拟磁盘故障有三个优点,首先应用程序感知到的设备故障与通过物理插拔磁盘是一致的,其次模拟过程简单方便,再次容易自动化,提升测试效率。
如何在内核中阻断磁盘处理程序?内核是随操作系统发布时安装在服务器上的核心代码,不可能在内核代码中预先设计并开发驻留故障程序。那怎么把故障程序注入到内核代码里?这里有必要了解两个强大的内核跟踪工具SystemTap和KProbes!
先介绍KProbes。KProbes是Linux中一个轻量级内核调试工具,它可以将程序断点插入到正在运行的内核之中,劫持内核代码执行流程。KProbes 提供了一个强行进入任何内核函数并从中断处理程序中无干扰地收集内核信息的接口。使用KProbes可以轻松地收集处理器寄存器和全局数据结构等调试信息。开发者甚至可以使用 Kprobes来修改寄存器值和全局数据结构的值。最新的KProbes调用了Ftrace内核跟踪框架(出现时间晚于KProbes)提供的一些服务来实现自己的部分接口,但是整体上不影响KProbes对外提供的调试功能。
当运用KProbes跟踪某个内核函数后,该内核函数入口地址的指令被修改成Ftrace提供的特殊指令。该指令修改了内核函数的初始执行流程,在进入内核函数之前执行KProbes指定的处理程序。如下图二所示,该内核函数入口地址的初始指令是nopl(空指令),KProbes生效后,该地址的指令变成了callq ftrace_regs_caller(调用Ftrace框架入口函数)。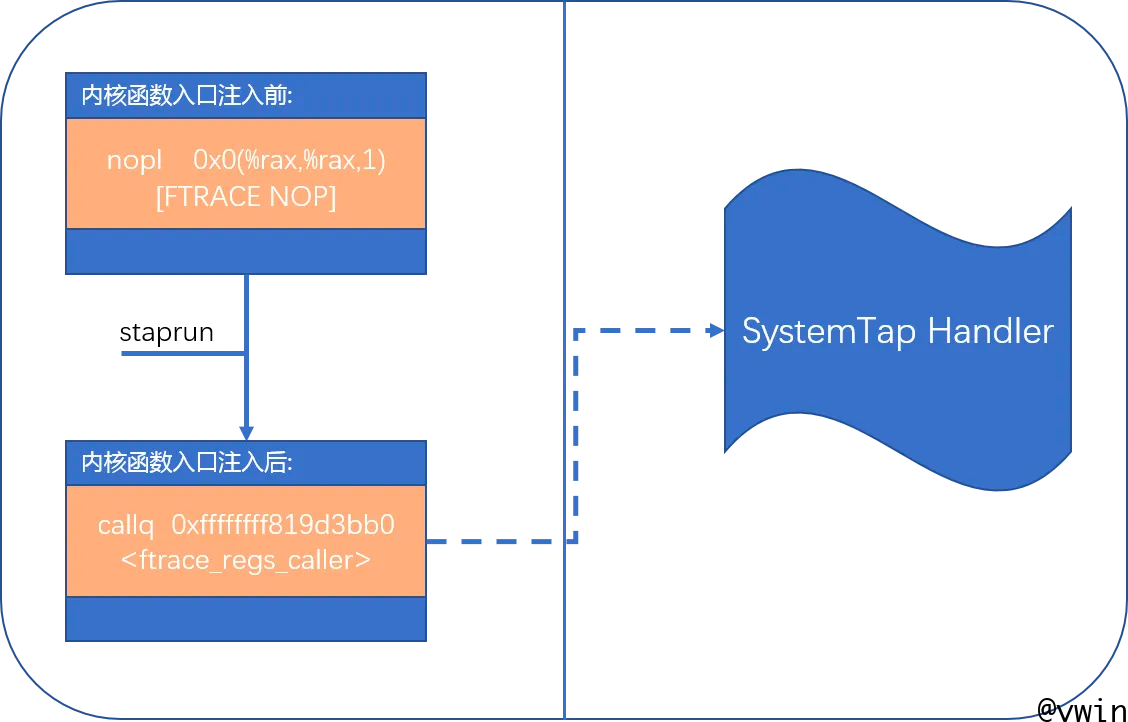
理解了KProbes后,掌握SystemTap就很简单了。Systemtap基于KProbes机制实现了内核函数动态跟踪,即最终使用KProbes提供的接口。但对于Systemtap来讲,它提供了一个简单的命令行接口和强大的脚本语言,同时预定义了丰富的脚本库,因此用户可以更简单,更安全地跟踪内核函数。
实现
这篇文章主要介绍如何利用SystemTap模拟磁盘故障;应用程序能够感知到的常见磁盘故障比如扇区读写错误(EIO),读写慢盘,读写超时无响应等等。通过SystemTap在内核磁盘处理函数调用路径上注入特殊代码,可以模拟大部分磁盘故障。首先介绍一下Linux内核中SCSI子系统的设计架构。SCSI内核模块分为三个层次,包括SCSI Upper Layer,SCSI Mid Layer, SCSI Lower Layer;
SCSI 子系统的较高层(Upper Layer)代表的是内核(设备级)最高级别的接口。它由一组虚拟设备驱动程序组成,比如块设备(SCSI 磁盘和 SCSI CD-ROM)和字符设备(SCSI 磁带和 SCSI Generic)。较高层接受来自上层(比如 VFS)的请求并将其转换成 SCSI 请求。较高层负责完成 SCSI 命令并将状态信息通知上层。SCSI中间层是 SCSI 较高层和较低层的公共服务层。它提供了很多可供较高层和较低层驱动器使用的函数,因而可以充当这两层间的连接层。在最低层的是一组驱动程序,称为SCSI底层驱动器。它们是一些可与物理设备(比如 HBA)匹配的特定驱动程序。LLD提供了自公共中间层到特定于设备的 HBA 的一种抽象。每个LLD都提供了到特定底层硬件的接口,但所使用的到中间层的接口却是一组标准接口。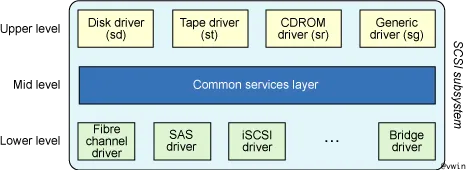
这篇文章使用到的SCSI内核处理函数位于子系统的中间层,包括了scsi_dispatch_cmd,scsi_decide_disposition,以及位于Linux Block Device子系统的部分通用函数比如blk_complete_request。下面展示SystemTap如何通过探测SCSI内核函数来模拟扇区读请求EIO故障。其中第一个探测点scsi_decide_dispostion在SCSI命令被下层驱动程序处理完成后,向上层返回时被调用;如果参数中$scmd是故障磁盘的读写请求SCSI命令,则修改该命令中的SCSI Sense Buffer状态值,当该SCSI命令返回到上层块设备处理函数时,状态值被解释为SCSI读请求错误。第二个探测点scsi_dispatch_cmd在SCSI命令被下发到物理磁盘驱动程序之前被调用;在探测点处理程序内人为地破坏了命令的关键结构成员值,故意引发下层驱动程序错误。通过一前一后两个探测点有安排地篡改SCSI命令结构值,到达模拟故障磁盘的效果。图三中红色方框内为两处探测点的关键处理代码,分别修改了SCSI命令中的关键数据结构值,构造了SCSI磁盘故障。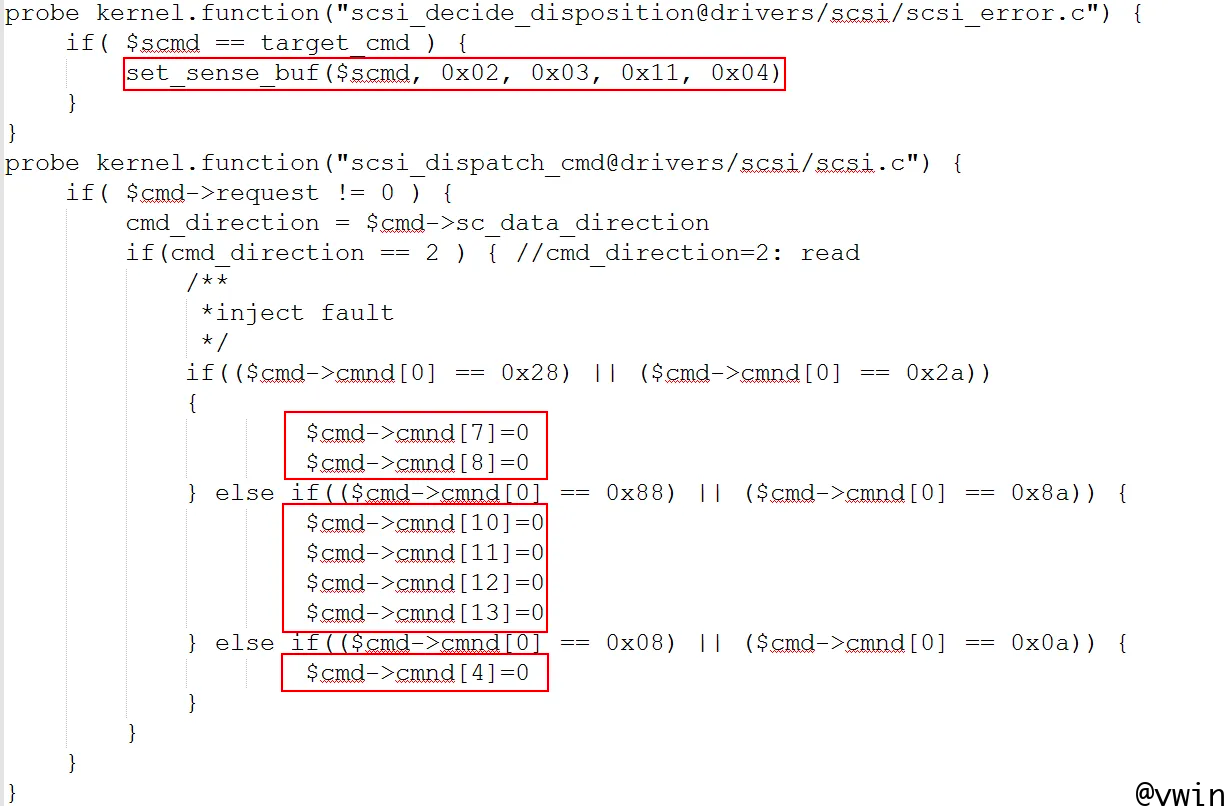
演示
为了进一步方便地模拟磁盘故障,进而为自动化各种故障测试场景做准备,这篇文章中使用了Linux Shell脚本进一步封装了SystemTap的运行接口与命令。最终通过一条命令进行磁盘故障模拟的执行。下图四与图五演示了如何使用封装后的脚本模拟慢盘和读请求EIO的磁盘故障。这个Shell脚本实现了SystemStap运行环境检查,安装故障模拟内核模块,发起故障模拟,移除故障模拟,以及最后清理运行环境。实现了故障模拟过程的闭环处理
演示一:模拟慢盘故障
这个演示模拟磁盘响应IO延时异常增大的故障;重点关注第下图第三个红色方框中的命令,该命令需要五个参数,其中第一个参数和第二个参数指定了模拟故障的磁盘设备区间,第三个和第四个参数指定了模拟故障的扇区区间,第五参数指定了慢盘的时长。演示中的参数表示主设备号从/dev/sdb到/dev/sdc的每个磁盘第200扇区至第220扇区模拟3秒慢盘。接下来发起一个dd命令验证模拟效果,通过strace工具检测read()调用的执行时间为2.97秒,符合预期。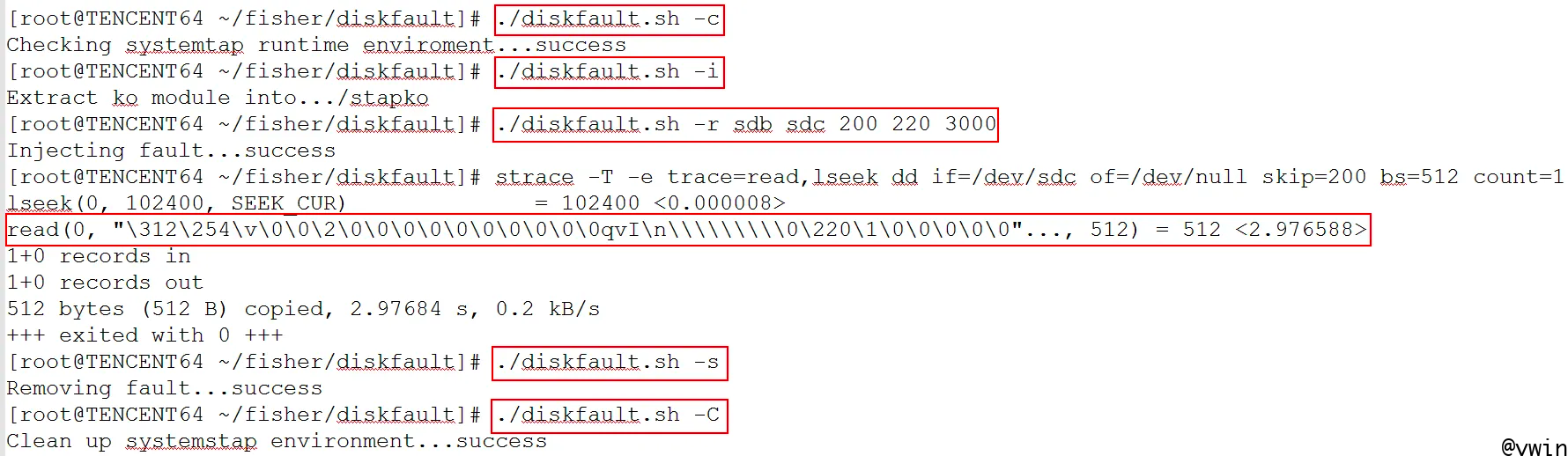
演示二:模拟EIO故障
这个演示模拟磁盘扇区读IO错误的故障;同样重点关注第下图第三个红色方框中的命令,该命令需要四个参数,其中第一个参数和第二个参数指定了模拟故障的磁盘设备区间,第三个和第四个参数指定了模拟故障的扇区区间。演示中的参数表示主设备号从/dev/sdb到/dev/sdc的每个磁盘第200扇区至第220扇区模拟EIO故障。接下来发起一个dd命令验证模拟效果,通过strace工具检测read()调用返回EIO(Input/output error),符合预期。另外当第五个红色框内的故障命令拆除故障后,再次访问同一磁盘扇区,系统调用read()正常返回扇区数据。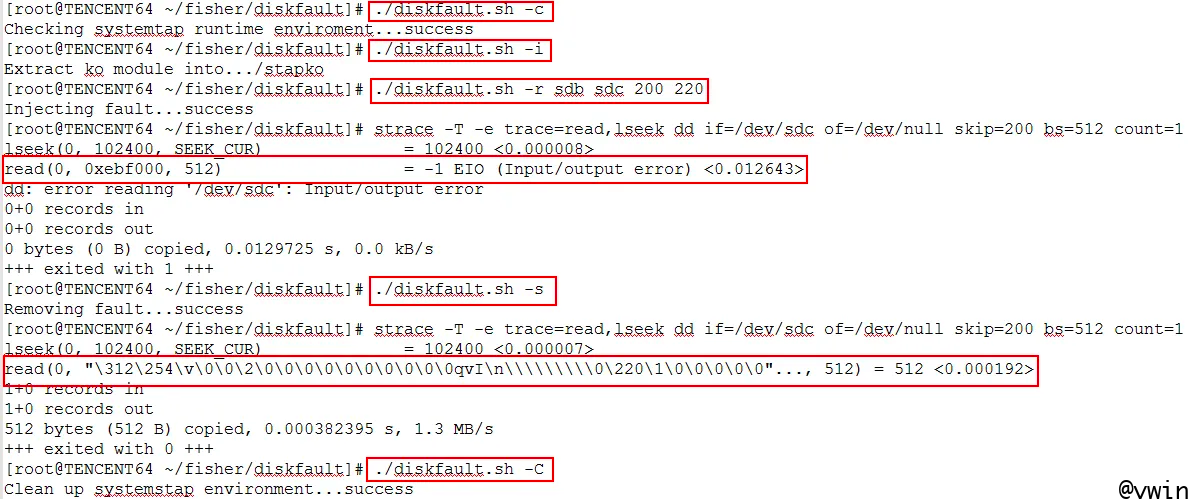
总结
截至目前,这篇文章所介绍的磁盘故障模拟方式可以方便地模拟全盘或部分扇区读错误(EIO)故障,自定义(慢盘时长)慢盘故障。不需要定制内核代码,使用接口非常简单,可以推广到更复杂的测试场景,以及为接下来的测试用例自动化提供基础性工具。下一步计划包括实现其他的磁盘故障比如写故障,超时故障;进一步整合到自动化测试用例中,实现测试用例的端到端自动化。