单测系列-C++
总结在C++中如何做单测,本文介绍了单测是什么以及C++常用的单测框架和工具
单元测试
单元测试是什么
单元是应用的最小可测试部件。在过程化编程中,一个单元就是单个程序、函数、过程等;对于面向对象编程,最小单元就是方法,包括基类、超类、抽象类等中的方法。单元测试就是软件开发中对最小单位进行正确性检验的测试工作。
不同地方对单元测试有的定义可能会有所不同,但有一些基本共识:
- 单元测试是比较底层的,关注代码的局部而不是整体。
- 单元测试是开发人员在写代码时候写的。
- 单元测试需要比其他测试运行得快。
单元测试的意义
- 提高代码质量。代码测试都是为了帮助开发人员发现问题从而解决问题,提高代码质量。
- 尽早发现问题。问题越早发现,解决的难度和成本就越低。
- 保证重构正确性。随着功能的增加,重构(修改老代码)几乎是无法避免的。很多时候我们不敢重构的原因,就是担心其它模块因为依赖它而不工作。有了单元测试,只要在改完代码后运行一下单测就知道改动对整个系统的影响了,从而可以让我们放心的重构代码。
- 简化调试过程。单元测试让我们可以轻松地知道是哪一部分代码出了问题。
- 简化集成过程。由于各个单元已经被测试,在集成过程中进行的后续测试会更加容易。
- 优化代码设计。编写测试用例会迫使开发人员仔细思考代码的设计和必须完成的工作,有利于开发人员加深对代码功能的理解,从而形成更合理的设计和结构。
- 单元测试是最好的文档。单元测试覆盖了接口的所有使用方法,是最好的示例代码。而真正的文档包括注释很有可能和代码不同步,并且看不懂。
单元测试用例编写的原则
理论原则
- 快。单元测试是回归测试,可以在开发过程的任何时候运行,因此运行速度必须快
- 一致性。代码没有改变的情况下,每次运行得结果应该保持确定且一致
- 原子性。结果只有两种情况:Pass / Fail
- 用例独立。执行顺序不影响;用例间没有状态共享或者依赖关系;用例没有副作用(执行前后环境状态一致)
- 单一职责。一个用例只负责一个场景
- 隔离。功能可能依赖于数据库、web访问、环境变量、系统时间等;一个单元可能依赖于另一部分代码,用例应该解除这些依赖
- 可读性。用例的名称、变量名等应该具有可读性,直接表现出该测试的目标
- 自动化。单元测试需要全自动执行。测试程序不应该有用户输入;测试结果应该能直接被电脑获取,不应该由人来判断。
规约原则
在实际编写代码过程中,不同的团队会有不同团队的风格,只要团队内部保持有一定的规约即可,比如:
- 单元测试文件名必须以xxx_test.go命名
- 方法必须是TestXxx开头,建议风格保持一致(驼峰或者下划线)
- 方法参数必须 t *testing.T
- 测试文件和被测试文件必须在一个包中
衡量原则
单元测试是要写额外的代码的,这对开发同学的也是一个不小的工作负担,在一些项目中,我们合理的评估单元测试的编写,我认为我们不能走极端,当然理论上来说全写肯定时好的,但是从成本,效率上来说我们必须做出权衡,衡量原则如下:
- 优先编写核心组件和逻辑模块的测试用例
- 逻辑类似的组件如果存在多个,优先编写其中一种逻辑组件的测试用例
- 发现Bug时一定先编写测试用例进行Debug
- 关键util工具类要编写测试用例,这些util工具适用的很频繁,所以这个原则也叫做热点原则,和第1点相呼应。
- 测试用户应该独立,一个文件对应一个,而且不同的测试用例之间不要互相依赖。
- 测试用例的保持更新
单元测试用例设计方法
规范(规格)导出法
规范(规格)导出法将需求”翻译“成测试用例。
例如,一个函数的设计需求如下:
1 | 函数:一个计算平方根的函数 |
在这个规范中有3个陈述,可以用两个测试用例来对应:
| 编号 | 用例 |
|---|---|
| 1 | 输入4,输出2 |
| 2 | 输入-1,输出0 |
等价类划分法
等价类划分法假定某一特定的等价类中的所有值对于测试目的来说是等价的,所以在每个等价类中找一个之作为测试用例。
按照 [输入条件][有效等价类][无效等价类] 建立等价类表,列出所有划分出的等价类
- 为每一个等价类规定一个唯一的编号
- 设计一个新的测试用例,使其尽可能多地覆盖尚未被覆盖地有效等价类。重复这一步,直到所有的有效等价类都被覆盖为止
- 设计一个新的测试用例,使其仅覆盖一个尚未被覆盖的无效等价类。重复这一步,直到所有的无效等价类都被覆盖为止
例如,注册邮箱时要求用6~18个字符,可使用字母、数字、下划线,需以字母开头。
| 有效等价类 | 无效等价类 |
|---|---|
| 6~18个字符(1) | 少于6个字符(2) 多余18个字符(3) 空(4) |
| 包含字母、数字、下划线(5) | 除字母、数字、下划线的特殊字符(6) 非打印字符(7) 中文字符 (8) |
| 以字母开头(9) | 以数字或下划线开头(10) |
测试用例
| 编号 | 输入数据 | 覆盖等价类 | 预期结果 |
|---|---|---|---|
| 1 | test_111 | (1)、(5)、(9) | 合法输入 |
| 2 | t_11 | (2)、(5)、(9) | 非法输入 |
| 3 | testtesttest_12345678 | (3)、(5)、(9) | 非法输入 |
| 4 | NULL | (4) | 非法输入 |
| 5 | test!@1111 | (1)、(6)、(9) | 非法输入 |
| 6 | test 1111 | (1)、(7)、(9) | 非法输入 |
| 7 | test测试1111 | (1)、(8)、(9) | 非法输入 |
| 8 | _test111 | (1)、(5)、(10) | 非法输入 |
边界值分析法
边界值分析法使用与等价类测试方法相同的等价类划分,只是边界值分析假定 错误更多地存在于两个划分的边界上。
边界值测试在软件变得复杂的时候也会变得不实用。边界值测试对于非向量类型的值(如枚举类型的值)也没有意义。
例如,和4.1相同的需求,划分(ii)的边界为0和最大正实数;划分(i)的边界为最小负实数和0。由此得到以下测试用例:
- 输入 {最小负实数}
- 输入 {绝对值很小的负数}
- 输入 0
- 输入 {绝对值很小的正数}
- 输入 {最大正实数}
基本路径测试法
基本路径测试法是在程序控制流图的基础上,通过分析控制构造的环路复杂性,导出基本可执行路径集合,从而设计测试用例的方法。设计出的测试用例要保证在测试中程序的每个可执行语句至少执行一次。
基本路径测试法的基本步骤:
- 程序的控制流图:描述程序控制流的一种图示方法。
- 程序圈复杂度:McCabe复杂性度量。从程序的环路复杂性可导出程序基本路径集合中的独立路径条数,这是确定程序中每个可执行语句至少执行一次所必须的测试用例数目的上界。
- 导出测试用例:根据圈复杂度和程序结构设计用例数据输入和预期结果。
- 准备测试用例:确保基本路径集中的每一条路径的执行。
常用C++单测框架
常用的C++单测对比
| 编号 | Google test | Catch 2 | CppUTest |
|---|---|---|---|
| 特点 | 成熟、兼容性好 简洁、有效率 常用、学习资源多 |
框架只有一个catch.hpp、集成轻松 有Given-When-Then分区,适合BDD行为驱动开发 无自带Mock框架 |
可以检测内存泄露 输出更简洁 适合在嵌入式系统项目中使用 |
| Mock框架 | Google Mock | 无自带Mock框架 | CppUMock |
| 推荐指数 | ★★★★★ | ★★★☆☆ | ★★☆☆☆ |
一般情况下,我们推荐使用Google Test搭配Google Mock。如果项目有特殊需求或更适合其他框架,也可以考虑。
根据实际使用频率,在以下部分,Google Test和Google Mock的介绍更为详细;对于其他框架,这里介绍它们的主要特点, 具体使用方法,可以查阅各自文档。
Google Test
Google Test是目前比较成熟而且最常用的C++单元测试框架之一。
基本概念
- 断言(Assertions) 是检查条件是否为真的语句。断言的结果可能是成功或者失败, 而失败又分为非致命失败或致命失败。如果发生致命失败,测试进程将中止当前运行,否则它将继续运行。
- 测试(Test) 使用断言来验证被测试代码的行为。如果测试崩溃或断言失败,则测试失败;否则测试成功。
- 测试套件(Test Suite) 包含一个或多个测试(Test)。当测试套件中的多个测试需要共享通用对象和子例程时, 可以将它们放入测试夹具(Test Fixture)。
- 测试程序(Test Program) 可以包含多个测试套件。
断言
- Google Test中,断言(Assertions) 是类似函数调用的宏。断言失败时,googletest会输出断言的源文件和 行号位置以及失败消息;我们还可以提供自定义失败消息,该消息将附加到googletest消息中。
- 断言成对出现(ASSERT_*和EXPECT_*),它们测试的对象相同,但对当前运行有不同的影响。ASSERT_*版本失败时 会产生致命故障,并中止当前函数(不一定是整个TEST)运行。EXPECT_*版本会产生非致命故障,不会停止当前函数运行。 通常EXPECT_*是首选,因为可以在测试中报告多个故障。但是如果在断言失败时继续执行没有意义,则应使用ASSERT_*。
- 要提供自定义失败消息,只需使用<< 运算符或此类运算符的序列将其流式传输到宏中即可 。一个例子:以下是一些最常用的断言,如果需要查阅其他断言,可以前往googletest的官方文档。
1
2
3
4
5ASSERT_EQ(x.size(), y.size()) << "x和y长度不同";
for (int i = 0; i < x.size(); ++i) {
EXPECT_EQ(x[i], y[i]) << "x和y元素存在不同:" << i;
}
基本断言
condition 是返回true/false的变量、布尔表达式、函数调用等,以下断言对其进行验证。
| 失败时中断执行的断言 | 失败时不中断执行的断言 | 断言成功情况 |
|---|---|---|
| ASSERT_TRUE(condition); | EXPECT_TRUE(condition); | condition为真 |
| ASSERT_FALSE(condition); | EXPECT_FALSE(condition); | condition为假 |
例如:在ASSERT_TRUE(condition)中,当condition为true时,符合断言,不影响执行;当condition
为false时,不符合断言,且由于是ASSERT,当前执行中断。
普通比较型断言
val1和val2是两个可用==、!=、>、<等运算符进行比较的值,以下断言对其进行比较。
| 失败时中断执行的断言 | 失败时不中断执行的断言 | 断言成功情况 |
|---|---|---|
| ASSERT_EQ(val1, val2); | EXPECT_EQ(val1, val2); | val1 == val2 |
| ASSERT_NE(val1, val2); | EXPECT_NE(val1, val2); | val1 != val2 |
| ASSERT_LT(val1, val2); | EXPECT_LT(val1, val2); | val1 < val2 |
| ASSERT_LE(val1, val2); | EXPECT_LE(val1, val2); | val1 <= val2 |
| ASSERT_GT(val1, val2); | EXPECT_GT(val1, val2); | val1 > val2 |
| ASSERT_GE(val1, val2); | EXPECT_GE(val1, val2); | val1 >= val2 |
例如:在ASSERT_GT(val1, val2)中,只有当val1 > val2时,符合断言,不影响执行;当val1 <= val2时,
不符合断言,且由于是ASSERT,当前执行中断。
C字符串比较型断言
str1和str2是两个C字符串,以下断言对它们的值进行比较;如果要比较两个std::string对象,直接用之前
提到的EXPECT_NE,EXPECT_NE等。
| 失败时中断执行的断言 | 失败时不中断执行的断言 | 断言成功情况 |
|---|---|---|
| ASSERT_STREQ(str1,str2); | EXPECT_STREQ(str1,str2); | 这两个C字符串具有相同的内容 |
| ASSERT_STRNE(str1,str2); | EXPECT_STRNE(str1,str2); | 两个C字符串的内容不同 |
| ASSERT_STRCASEEQ(str1,str2); | EXPECT_STRCASEEQ(str1,str2); | 忽略大小写,两个C字符串的内容相同 |
| ASSERT_STRCASENE(str1,str2); | EXPECT_STRCASENE(str1,str2) | 忽略大小写,两个C字符串的内容不同 |
例如:char *str1 = "ABC";``char *str2 = "ABC";,EXPECT_STREQ(str1, str2);断言通过,
因为它们的内容一样;而EXPECT_EQ(str1, str2);断言失败,因为它们的地址不一样。
注意:一个NULL指针和一个空字符串""是不同的。
浮点数比较型断言
val1和val2是两个浮点数,以下断言对其进行比较。
| 失败时中断执行的断言 | 失败时不中断执行的断言 | 断言成功情况 |
|---|---|---|
| ASSERT_FLOAT_EQ(val1, val2); | EXPECT_FLOAT_EQ(val1, val2); | 这两个float值几乎相等 |
| ASSERT_DOUBLE_EQ(val1, val2); | EXPECT_DOUBLE_EQ(val1, val2); | 这两个double值几乎相等 |
以下断言可以选择可接受的误差范围:
| 失败时中断执行的断言 | 失败时不中断执行的断言 | 断言成功情况 |
|---|---|---|
| ASSERT_NEAR(val1, val2, abs_error); | EXPECT_NEAR(val1, val2, abs_error); | val1和val2的差的绝对值不超过abs_error |
明确的成功和失败
- 明确生成成功:
SUCCEED();生成一个成功,但这不代表整个测试就成功了。- 明确生成失败:
FAIL();生成致命错误ADD_FAILURE();生成非致命错误。ADD_FAILURE_AT("file_path",line_number);生成非致命错误,输出文件名和行号。
例如:
1 | if(condition) { |
效果上等同于
1 | ASSERT_TRUE(condition); |
只是ASSERT_TRUE失败时可以输出condition的具体值。当但我们需要验证的condition很复杂时,
或者需要很多个if..else...分支来验证彼此互斥的情况以保证覆盖到每一种可能性时,SUCCEED()、FAIL()等
明确的成功/失败可能是更好的选择。
异常断言
这些断言验证一段代码(statement)是否抛出(或不抛出)给定类型的异常:
| 失败时中断执行的断言 | 失败时不中断执行的断言 | 断言成功情况 |
|---|---|---|
| ASSERT_THROW(statement, exception_type); | EXPECT_THROW(statement, exception_type); | statement抛出给定类型的异常 |
| ASSERT_ANY_THROW(statement); | EXPECT_ANY_THROW(statement); | statement抛出任何类型的异常 |
| ASSERT_NO_THROW(statement); | EXPECT_NO_THROW(statement); | statement不抛出任何异常 |
使用已有布尔函数
当predN是一个有N个参数,返回布尔值的函数时,以下断言可以获取更好的错误信息。
| 失败时中断执行的断言 | 失败时不中断执行的断言 | 断言成功情况 |
|---|---|---|
| ASSERT_PRED1(pred1, val1); | EXPECT_PRED1(pred1, val1); | pred1(val1)为真 |
| ASSERT_PRED2(pred2, val1, val2); | EXPECT_PRED2(pred2, val1, val2); | pred2(val1, val2)为真 |
| … | … | … |
例如:isComparable(Object o1, Object o2)是一个返回布尔值的函数。我们可以有以下选择,
都能达到验证函数调用结果的目的:
ASSERT_TRUE(isComparable(obj1, obj2));ASSERT_PRED2(isComparable, obj1, obj2);
区别在于:当断言失败时,ASSERT_TRUE只会告知函数最后的返回值是false;而ASSERT_TRUE同时
会输出val1、val2的值。
测试
创建一个测试的步骤:
- 使用
TEST()宏定义和命名测试功能。 - 在
TEST()宏内,构造出达到测试状态的函数、变量 - 使用断言指定函数、变量期望的返回值、值。
1
2
3
4TEST(MessageTestSuite, BodyLengthNegative) {
... 构造 ...
... 断言 ...
}
TEST()第一个参数是Test Suite的名称,第二个参数是Test Suite内的Test名称。这两个名称都必须是有效的
C++标识符,并且它们不应包含任何下划线(_)。测试的全名包括Test Suite名和Test名。来自不同Test Suite的
测试可以具有相同的Test名。它们都不是变量,也不是字符串。
在上面的例子中,这个测试的名称是BodyLengthNegative,Test Suite的名称是MessageTestSuite。
测试夹具:多个测试有共有的数据配置
如果多个测试有共有的数据配置,可以使用测试夹具(Test Fixture)将共用部分提取出来重复利用。
要创建一个测试夹具:
- 创建一个继承
::testing::Test的类。从protected开始这个类,因为我们要从子类访问夹具成员。 - 在类内部,声明计划使用的任何对象。
- 如有必要,编写默认的
constructor或SetUp()函数为每个测试准备对象。 - 如有必要,编写一个
destructor或TearDown()函数以释放在SetUp()中分配的任何资源。 - 如有必要,定义一些共享的类函数
当使用测试夹具是,需要使用TEST_F()而不是TEST()
1 | class TestFixtureName : public ::testing::Test { |
那上面这个例子来说,对于每个TEST_F()测试,googletest将在运行时
- 创建一个新的测试夹具(Test Fixture)对象
- 通过
SetUp()对其进行初始化 - 运行该
TEST_F()测试 - 通过调用进行清理
TearDown() - 然后删除该测试夹具(Test Fixture)对象
所以,虽然多个TEST_F共用同一部分代码,但共同代码会每个TEST_F都独立执行一次。同一测试套件中的不同测试具有不同的测试夹具对象。一个测试对测试夹具所做的任何更改均不会影响其他测试。
Catch 2
Catch2 仅有头部文件(header only),所以它的第一个优点是可以轻易地放入任何项目中进行使用。只需要 #include "catch.hpp" 就可以在当前文件使用 Catch
REQUIRE
Catch的基础使用方法也很简单。
1 |
|
SECTIONS
Catch的SECTION相当于GTEST里夹具(fixture)的功能。对每一个SECTION,TEST_CASE 都从头开始执行。
1 | TEST_CASE( "vectors can be sized and resized", "[vector]" ) { |
标签
Catch提供标签特性。
1 | TEST_CASE( "A", "[widget]" ) { /* ... */ } |
"[widget]"选取 A、B、D."[gadget]"选取 C、D."[widget][gadget]"只选取 D"[widget],[gadget]"所有A、B、C、D.- 还有一些特殊标签指定特殊行为
特点总结
- 框架只有一个
catch.hpp、集成轻松 - 有Given-When-Then分区,适合BDD行为驱动开发
- 无自带Mock框架
CppUTest
main和test
main.cpp:
1 |
|
test.cpp:
1 |
|
断言
CHECK(boolean condition)检查任何布尔结果。CHECK_TEXT(boolean condition, text)检查任何布尔结果,并在失败时输出文本。CHECK_FALSE(condition)检查任何布尔结果CHECK_EQUAL(expected, actual)使用==检查实体之间的相等性。因此,如果有一个支持operator==()的类,则可以使用此宏比较两个实例。CHECK_COMPARE(first, relop, second)检查在两个实体之间是否存在关系运算符。失败时,打印两个操作数求和的结果。CHECK_THROWS(expected_exception, expression)检查表达式是否抛出expected_exception(例如std::exception)。CHECK_THROWS仅在使用标准C ++库(默认)构建CppUTest时可用。STRCMP_EQUAL(expected, actual)使用strcmp()检查const char *字符串是否相等。STRNCMP_EQUAL(expected, actual, length)使用strncmp()检查const char *字符串是否相等。STRCMP_NOCASE_EQUAL(expected, actual)不考虑大小写,检查const char *字符串是否相等。
特点
- 可以检测内存泄露
- 输出更简洁
- 使用在嵌入式系统项目中使用
Google Mock
Google Mock一般来说和Google Test搭配使用,但Google Test也可以和其他Mock框架一起使用。
本部分是Google Mock基础常用的用法,如需要特殊用法,请查阅Google Mock官方文档。
Fake、Mock、Stub
- Fake对象有具体的实现,但采取一些捷径,比如用内存替代真实的数据库读取。
- Stub对象没有具体的实现,只是返回提前准备好的数据。
- Mock对象和Stub类似,只是在测试中需要调用时,针对某种输入指定期望的行为。Mock和Stub的区别是,
Mock除了返回数据还可以指定期望以验证行为。
简单例子:Mock Turtle
Turtle类:
1 | class Turtle { |
MockTurtle类:
1 |
|
创建Mock类的步骤:
MockTurtle继承Turtle找到
Turtle的一个虚函数在
public:的部分中,写一个MOCK_METHOD();将虚函数函数签名复制进
MOCK_METHOD();中,加两个逗号:一个在返回类型和函数名之间另一个在函数名和参数列表之间例如:
void PenDown()有三部分:void、PenDown和(),这三部分就是MOCK_METHOD的前三个参数如果要模拟
const方法,添加一个包含(const)的第4个参数(必须带括号)。建议添加
override关键字。所以对于const方法,第四个参数变为(const, override),对于非const方法,第四个参数变为(override)。这不是强制性的。重复步骤直至完成要模拟的所有虚拟函数。
在测试中使用Mock
在测试中使用Mock的步骤:
- 从
testing名称空间导入gmock.h的函数名(每个文件只需要执行一次)。 - 创建一些Mock对象。
- 指定对它们的期望(方法将被调用多少次?带有什么参数?每次应该做什么(对参数做什么、返回什么值)?等等)。
- 使用Mock对象;可以使用googletest断言检查结果。如果mock函数的调用超出预期或参数错误,将会立即收到错误消息。
- 当Mock对象被销毁时,gMock自动检查对模拟的所有期望是否得到满足。
1 |
|
在这个例子中,我们期望turtle的PenDown()至少被调用一次。如果在turtle对象被销毁时,PenDown()还没有被调用或者调用两次或以上,测试会失败。
指定期望
EXPECT_CALL(指定期望)是使用Google Mock的核心。EXPECT_CALL的作用是两方面的:
告诉这个Mock(假)方法如何模仿原始方法:
我们在
EXPECT_CALL中告诉Google Mock,某个对象的某个方法被第一次调用时,会修改某个参数,会返回某个值;第二次调用时,会修改某个参数,会返回某个值…….验证被调用的情况
我们在
EXPECT_CALL中告诉Google Mock,某个对象的某个方法总共会被调用N次(或大于N次、小于N次)。如果最终次数不符合预期,会导致测试失败。
基本语法
1 | EXPECT_CALL(mock_object, method(matchers)) |
mock_object是对象method(matchers)用于匹配相应的函数调用cardinality指定基数(被调用次数情况)action指定被调用时的行为
例子:
1 | using ::testing::Return; |
这个EXPECT_CALL()指定的期望是:在turtle这个Mock对象销毁之前,turtle的getX()函数会被调用五次。第一次返回100,第二次返回150,第三次及以后都返回200。指定期望后,5次对getX的调用会有这些行为。但如果最终调用次数不为5次,则测试失败。
参数匹配:哪次调用
1 | using ::testing::_; |
_相当于“任何”。100相当于Eq(100)。Ge(50)指参数大于或等于50。- 如果不关心参数,只写函数名就可以。比如
EXPECT_CALL(turtle, GoTo);。
基数:被调用几次
用Times(m),Times(AtLeast(n))等来指定期待的调用次数。
Times可以被省略。比如整个EXPECT_CALL只有一个WillOnce(action)相当于也说明了调用次数只能为1。
行为:该做什么
常用模式:如果需要指定前几次调用的特殊情况,并且之后的调用情况相同。使用一系列WillOnce()之后有WillRepeatedly()
除了用来指定调用返回值的Return(),Google Mock中常用行为中还有:SetArgPointee<N>(value),SetArgPointee将第N个指针参数(从0开始)指向的变量赋值为value。
比如void getObject(Object* response){...}的EXPECT_CALL:
1 | Object* a = new Object; |
就修改了传入的指针response,使其指向了一个我们新创建的对象。
如果有多个行为,应该使用DoAll(a1, a2, ..., an)。DoAll执行所有n个action并返回an的结果。
使用多个预期
例子:
1 | using ::testing::_; |
正常情况下,Google Mock以倒序搜索预期:如果和多个EXPECT_CALL都可以匹配,只有之前的,
距离调用最近的一个EXPECT_CALL()会被匹配。例如:
- 连续三次调用
Forward(10)会生错误因为它和#2匹配。 - 连续三次调用
Forward(20)不会有错误因为它和#1匹配。
一旦匹配,该预期会被一直绑定,即使执行次数达到上限之后,还是是生效的,这就是为什么三次调用Forward(10)超过了2号EXPECT_CALL的上限时,不会去试图绑定1号EXPECT_CALL而是报错的原因。
为了明确地让某一个EXPECT_CALL“退休”,可以加上RetiresOnSaturation(),例子:
1 | using ::testing::Return; |
在这个例子中,第一次GetX()调用和#2匹配,返回20,然后这个EXPECT_CALL就“退休”了;
第二次GetX()调用和#1匹配,返回10
Sequence
可以用sequence来指定期望匹配的顺序。
1 | using ::testing::Return; |
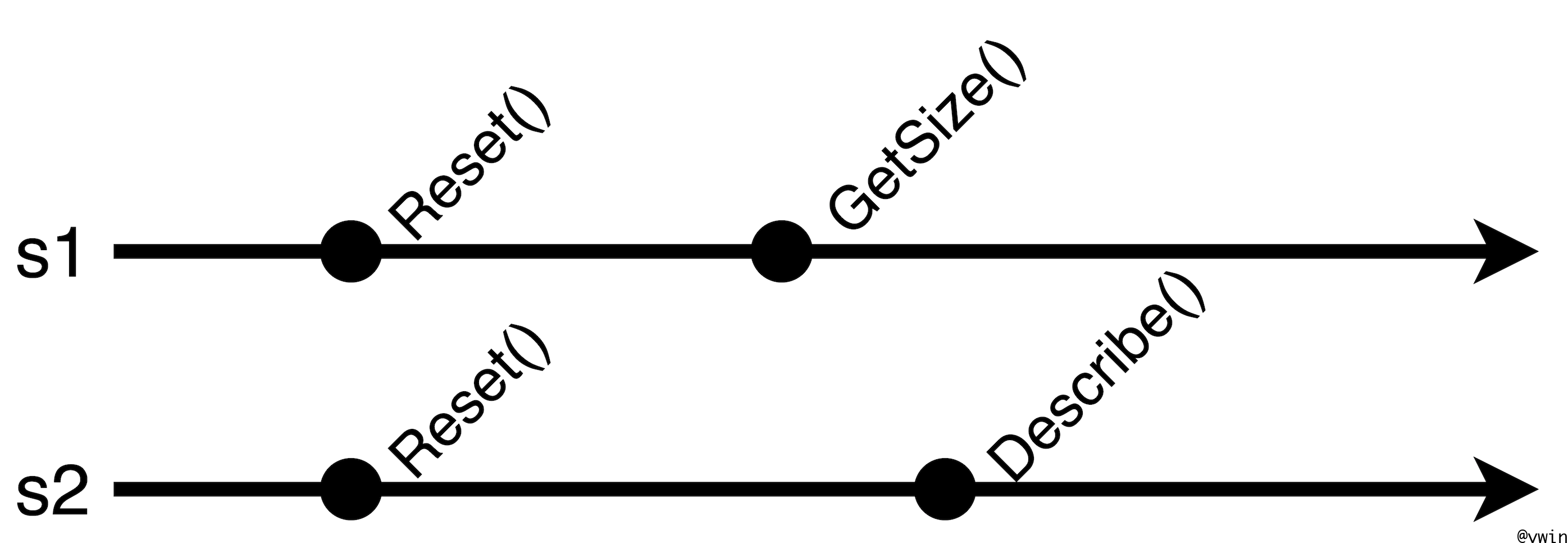
在上面的例子中,创建了两个Sequence s1和s2,属于s1的有Reset()和GetSize(),
所以Reset()必须在GetSize()之前执行。属于s2的有Reset()和Describe(A<const char*>()),
所以Reset()必须在Describe(A<const char*>())之前执行。所以,Reset()必须在GetSize()
和Describe()之前执行。而GetSize()和Describe()这两者之间没有顺序约束。
如果需要指定很多期望的顺序,有另一种用法:
1 | using ::testing::InSequence; |
在这种用法中,scope中(大括号中)的期望必须遵守严格的顺序。
更多
情景示例
在这部分,我们用一个示例项目来演示,如何在不同情景中使用
Google Test和Google Mock写单元测试用例。
项目结构
示例项目是一个C++命令行聊天室软件,包含服务器和客户端。
1 | . |
普通测试
如果被测试的函数不包含外部依赖,用Google Test基础的用法就可以完成用例编写。
原函数:
1 | void chat_message::body_length(std::size_t new_length) { |
这个函数很简单。就是给body_length_赋值但是有最大值限制。测试用例可以这样写:
1 | TEST(ChatMessageTest, BodyLengthNegative) { |
我们可以看到,对于这类函数,用例编写很直接简单,步骤都是构造变量,再用合适的Google Test的
宏来验证变量值或者函数调用返回值。
简单 Mock
原函数
1 | void chat_room::leave(chat_participant_ptr participant) { |
participants_ 的类型是 std::set<chat_participant_ptr>。这个函数的目的很明显,将一个participant从set中移除。
真实地创建一个聊天参与者participant对象可以条件比较苛刻或者成本比较高。为了有效率地验证这个函数,我们可以新建一些Mock的chat_participant_ptr而不用严格地去创建真实的participant对象。
chat_participant对象:
1 | class chat_participant { |
Mock对象:
1 | class mock_chat_participant : public chat_participant { |
测试用例:
1 | TEST(ChatRoomTest, leave) { |
Web请求
chat_room中有一个log(),依赖网络请求。原函数:
1 | std::string chat_room::log() { |
在单元测试中,我们只关心被测试部分的逻辑。为了测试这个函数,我们不应该创建真实的requester,应该使用mock。
http_request对象:
1 | class http_request { |
Mock对象:
1 | class mock_http_request : public http_request { |
测试用例:
1 | TEST(ChatRoomTest, log) { |
数据库访问
chat_room对象会将聊天者发送的消息存储在redis数据库中。当新用户加入时,chat_room对象从数据库
获取所有历史消息发送给该新用户。
join()函数:
1 | void chat_room::join(chat_participant_ptr participant) { |
message_dao对象:
1 | class message_dao { |
Mock对象:
1 | class mock_message_dao : public message_dao { |
测试用例:
1 | TEST(ChatRoomTest, join) { |
先创建mock对象,再指定函数调用的预期,最后指向被测试函数。我们可以看到,mock_dao指定了get_messages的
返回值时一个长度为3的vector,所以有3条消息会被deliver。
FAQ
单元测试源文件应该放在项目的什么位置?
一般来说,我们会在根目录创建一个tests文件夹,里面放单元测试部分的源代码,从而不会和被测试代码混在一起。
如果需要和其他测试(如接口测试、压力测试)等区分开来,可以
- 把
tests改成unittests、utests等,或者 - 在
tests创建不同子文件夹存放不同类型的测试代码。
Google Mock只能Mock虚函数,如果我想Mock非虚函数怎么办?
由于Google Mock(及其他大部分Mock框架)通过继承来动态重载机制的限制,一般来说Google Mock只能Mock虚函数。如果要mock非虚函数,官方文档提供这几种思路:
- Mock类和原类没有继承关系,在测试对象使用函数模板。在测试中,测试对象接受Mock类。
- 创建一个接口(抽象类),原类继承自这个接口(抽象类)。在测试中Mock这个接口(抽象类)。
这两种方法,都需要对代码进行一定的修改或重构。如果不想修改被测试代码。可以考虑使用hook技术替换被mock的部分从而mock一般函数。
使用TMock对非虚函数mock的例子:
mock函数
1 |
|
单测中应用tmock的方法和Google Mock基本一致。但在结束的时候需要使用TMOCK_CLEAR清除exception,
detach hook的函数,防止干扰其他单元测试。
Google Test官方文档中说测测试套件名称、测试夹具名称、测试名称中不应该出现下划线_。为什么?
TEST(TestSuiteName, TestName)生成名为TestSuiteName_TestName_Test的类。
下划线_是特殊的,因为C ++保留以下内容供编译器和标准库使用。所以开头和结尾有下划线很容易让生成的类的标识符不合法。
另一方面,下划线可能让不同测试生成相同的类。比如TEST(Time,Flies_Like_An_Arrow){...} 和TEST(Time_Flies,Like_An_Arrow){...} 都生成名为Time_Flies_Like_An_Arrow_Test的类。
测试输出里有很多Uninteresting mock function call警告怎么办?
创建的Mock的对象的某些调用如果没有相应匹配的EXPECT_CALL,Google Mock会生成这个警告。
为了去除这个警告,可以使用NiceMock。比如如果原本使用MockFoo nice_foo;新建mock对象的话,可以改成NiceMock<MockFoo> nice_foo;。NiceMock<MockFoo>是MockFoo的子类。
单测覆盖率
使用 Gcov 和 LCOV 度量 C/C++ 项目的代码覆盖率
什么是代码覆盖率?
代码覆盖率是对整个测试过程中被执行的代码的衡量,它能测量源代码中的哪些语句在测试中被执行,哪些语句尚未被执行。
为什么要测量代码覆盖率?
众所周知,测试可以提高软件版本的质量和可预测性。但是,你知道你的单元测试甚至是你的功能测试实际测试代码的效果如何吗?是否还需要更多的测试?
这些是代码覆盖率可以试图回答的问题。总之,出于以下原因我们需要测量代码覆盖率:
- 了解我们的测试用例对源代码的测试效果
- 了解我们是否进行了足够的测试
- 在软件的整个生命周期内保持测试质量
注:代码覆盖率不是灵丹妙药,覆盖率测量不能替代良好的代码审查和优秀的编程实践。
通常,我们应该采用合理的覆盖目标,力求在代码覆盖率在所有模块中实现均匀覆盖,而不是只看最终数字的是否高到令人满意。
举例:假设代码覆盖率只在某一些模块代码覆盖率很高,但在一些关键模块并没有足够的测试用例覆盖,那样虽然代码覆盖率很高,但并不能说明产品质量就很高。
代码覆盖率的指标种类
代码覆盖率工具通常使用一个或多个标准来确定你的代码在被自动化测试后是否得到了执行,常见的覆盖率报告中看到的指标包括:
- 函数覆盖率:定义的函数中有多少被调用
- 语句覆盖率:程序中的语句有多少被执行
- 分支覆盖率:有多少控制结构的分支(例如if语句)被执行
- 条件覆盖率:有多少布尔子表达式被测试为真值和假值
- 行覆盖率:有多少行的源代码被测试过
代码覆盖率是如何工作的?
代码覆盖率测量主要有以下三种方式:
Source code instrumentation - 源代码检测
将检测语句添加到源代码中,并使用正常的编译工具链编译代码以生成检测的程序集。这是我们常说的插桩,Gcov 是属于这一类的代码覆盖率工具。Runtime instrumentation - 运行时收集
这种方法在代码执行时从运行时环境收集信息以确定覆盖率信息。以我的理解 JaCoCo 和 Coverage 这两个工具的原理属于这一类别。Intermediate code instrumentation - 中间代码检测
通过添加新的字节码来检测编译后的类文件,并生成一个新的检测类。说实话,我 Google 了很多文章并找到确定的说明哪个工具是属于这一类的。
了解这些工具的基本原理,结合现有的测试用例,有助于正确的选择代码覆盖率工具。比如:
- 产品的源代码只有 E2E(端到端)测试用例,通常只能选择第一类工具,即通过插桩编译出的可执行文件,然后进行测试和结果收集。
- 产品的源代码有单元测试用例,通常选择第二类工具,即运行时收集。这类工具的执行效率高,易于做持续集成。
当前主流代码覆盖率工具
代码覆盖率的工具有很多,以下是我用过的不同编程语言的代码覆盖率工具。在选择工具时,力求去选择那些开源、流行(活跃)、好用的工具。
| 编程语言 | 代码覆盖率工具 |
|---|---|
| C/C++ | Gcov |
| Java | JaCoCo |
| JavaScript | Istanbul |
| Python | Coverage.py |
| Golang | cover |
最后,不要高估代码覆盖率指标
代码覆盖率不是灵丹妙药,它只是告诉我们有哪些代码没有被测试用例“执行到”而已,高百分比的代码覆盖率不等于高质量的有效测试。
- 首先,高代码覆盖率不足以衡量有效测试。相反,代码覆盖率更准确地给出了代码未被测试程度的度量。这意味着,如果我们的代码覆盖率指标较低,那么我们可以确定代码的重要部分没有经过测试,然而反过来不一定正确。具有高代码覆盖率并不能充分表明我们的代码已经过充分测试。
- 其次,100% 的代码覆盖率不应该是我们明确努力的目标之一。这是因为在实现 100% 的代码覆盖率与实际测试重要的代码之间总是需要权衡。虽然可以测试所有代码,但考虑到为了满足覆盖率要求而编写更多无意义测试的趋势,当你接近此限制时,测试的价值也很可能会减少。
借 Martin Fowler 在这篇测试覆盖率的文章说的一句话:1
2代码覆盖率是查找代码库中未测试部分的有用工具,然而它作为一个数字说明你的测试有多好用处不大。
C++覆盖率
介绍如何使用 Gcov 和 LCOV 对 C/C++ 项目进行代码覆盖率的度量。
对于想使用 Gcov 的人,为了说明它是如何工作的,准备了一段示例程序,运行这个程序之前需要先安装 GCC 和 LCOV。
如果没有环境或不想安装,可以直接查看示例仓库的 GitHub 仓库:Gcov示例
注:主分支 master 下面放的是源码,分支 coverage 下的 out 目录是最终的结果报告。
这是我的测试环境上的 GCC 和 lcov 的版本
1 | sh-4.2$ gcc --version |
Gcov 是如何工作的
Gcov 工作流程图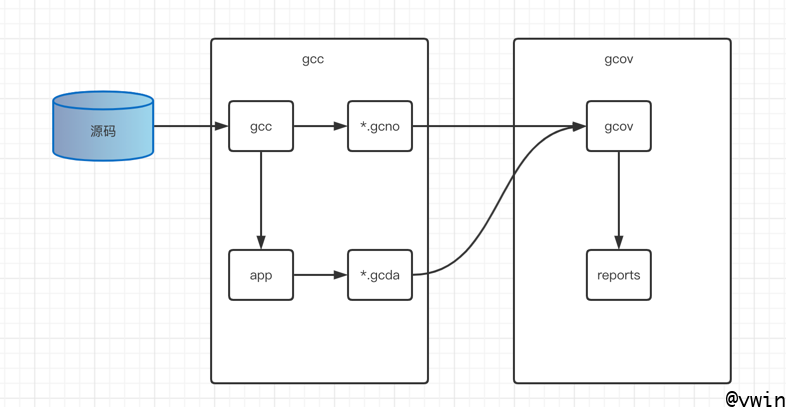
主要分三步:
- 在 GCC 编译的时加入特殊的编译选项,生成可执行文件,和 *.gcno;
- 运行(测试)生成的可执行文件,生成了 *.gcda 数据文件;
- 有了 *.gcno 和 *.gcda,通过源码生成 gcov 文件,最后生成代码覆盖率报告。
下面就开始介绍其中每一步具体是怎么做的。
编译
第一步编译,这里已经将编译用到的参数和文件都写在了 makefile 里了,只要执行 make 就可以编译了。
1 | make |
make 命令的输出
1 | sh-4.2$ make |
通过输出可以看到,这个程序在编译的时候添加了两个编译选项 -fprofile-arcs and -ftest-coverage。在编译成功后,不仅生成了 main and .o 文件,同时还生成了两个 .gcno 文件.
.gcno 记录文件是在加入 GCC 编译选项 -ftest-coverage 后生成的,在编译过程中它包含用于重建基本块图和为块分配源行号的信息。
如果使用的是cmake,则在CMakeLists.txt中加入
1 | set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -fprofile-arcs -ftest-coverage") |
运行可执行文件
在编译完成后,生成了 main 这个可执行文件,运行(测试)它:
1 | ./main |
运行 main 时输出
1 |
|
当运行 main 后,执行结果被记录在了 .gcda 这个数据文件里,查看当前目录下可以看到一共有生成了两个 .gcda 文件,每个源文件都对应一个 .gcda 文件。
1 |
|
生成报告
1 | make report |
生成报告的输出
1 | sh-4.2$ make report |
执行 make report 来生成 HTML 报告,这条命令的背后实际上主要执行了以下两个步骤:
- 在有了编译和运行时候生成的 .gcno 和 .gcda 文件后,执行命令 gcov main.c foo.c 即可生成 .gcov 代码覆盖率文件。
- 有了代码覆盖率 .gcov 文件,通过 LCOV 生成可视化代码覆盖率报告。
生成 HTML 结果报告的步骤如下:1
2
3
4
5
6
7
8
9
10
1. 生成 coverage.info 数据文件
lcov --capture --directory . --output-file coverage.info
2. 根据这个数据文件生成报告
genhtml coverage.info --output-directory out
常用的lcov命令:
1. lcov --extract xx.info '*/xx' '*/yy' -o res.info // 只保留xx.info中的xx和yy目录并输出到res.info
2. lcov --remove xx.info '*/xx' '*/yy' -o res.info //删除xx.info中的xx和yy目录并输出到res.info
3. lcov -a xx.info -a yy.info -o res.info //合并xx.info和yy.info并输出到res.info
收尾
上传过程中所有生成的文件可通过执行 make clean 命令来彻底删除掉。
make clean 命令的输出
1 |
|
旁注: 还有另外一个生成 HTML 报告的工具叫 gcovr,使用 Python 开发的,它的报告在显示方式上与 LCOV 略有不同。比如 LCOV 以目录结构显示, gcovr 以文件路径来显示,前者与代码结构一直因此我更倾向于使用前者。
结语
实践小结
和GoLang单元测试框架有些区别的是,GoLang自生就提供了自带的测试框架,也有第三方框架进行选择。
而C/C++/php等语言的单元测试框架则需要第三方提供和安装。
框架的使用,无非是一些语法糖的差异和使用的难易程度。不管使用什么语言,什么框架,最关键的是利用单元测试的思路,
写出解耦的、可测试的、易于维护的代码,保证代码的质量。
单元测试是一种手段,能够一定程度的改善生产力。凡事有度过犹不及,如果一味的盲目的追求测试覆盖率,
忽视了测试代码本身的质量,那么各种无效的单元测试反而带来了沉重的维护负担。因此单测的代码,本身也是代码,
也是和项目本身的代码一样,需要重构、维护的(好好写代码)。